|
接上一篇文章 【Python音视频技术】玩AI视频创作引发写Python音视频技术系列文章1---视频添加字幕 之前我想在视频中提取音频转换文字, 当时是用 PC剪映专业版搞定的, 详情见 【AI+应用】模仿爆款视频二次创作短视频操作步骤 。 这里我准备用python来实现类似功能。 先上自己简单写的示例代码: 这里的原视频用的【人工智能】AI视频二次创作演示
代码简单解释下, 先把视频转换成音频文件(这里转换成wav格式),然后SpeechRecognition离线识别文字。 需要注意的是SpeechRecognition支持语音文件类型:
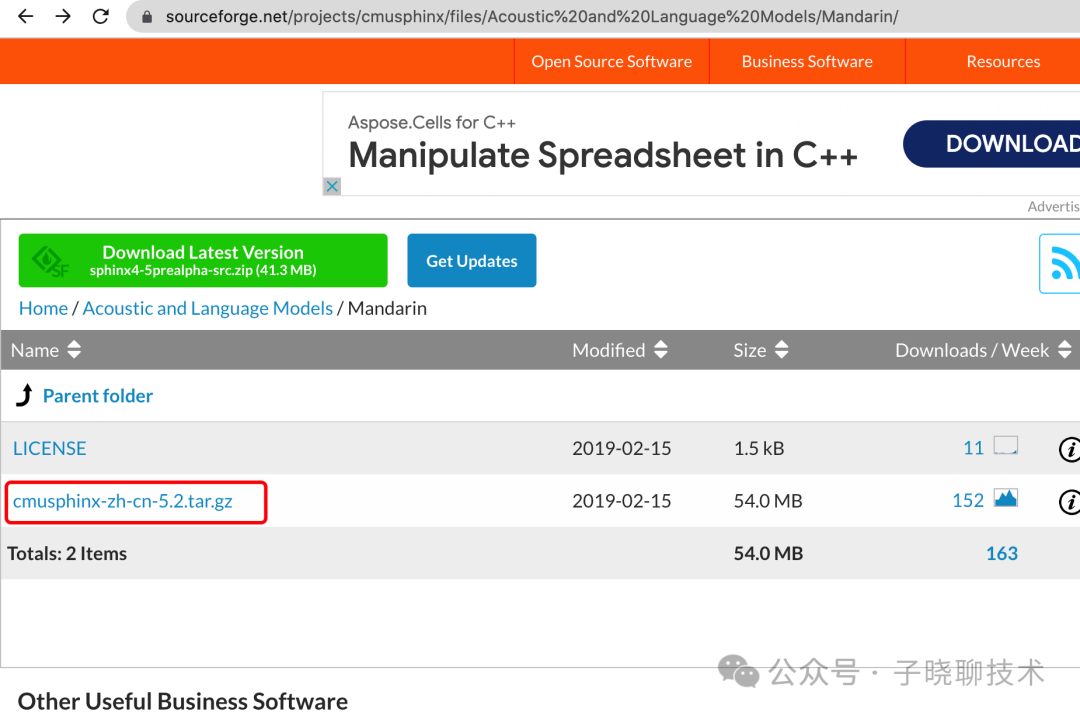
recognize_sphinx()语音识别器,它既可以联网工作,也可以离线工作,离线必须安装pocketsphinx库。 这里采用离线方式。 pip3 install SpeechRecognition pip3 install pocketsphinx 备注: moviePy安装可以参考上一篇文章,这里就不细写了。 python3 video_to_text.py 直接安装运行后会发现, 对应目录产生了音频文件, 生成的文字等待了很长时间,出来一堆牛头不对马嘴的英文。 这时候,我在想,应该是要找安装 中文声学模型、语言模型和字典文件。 参照网上的做法:先找中文包下载地址: https://sourceforge.net/projects/cmusphinx/files/Acoustic%20and%20Language%20Models/Mandarin/
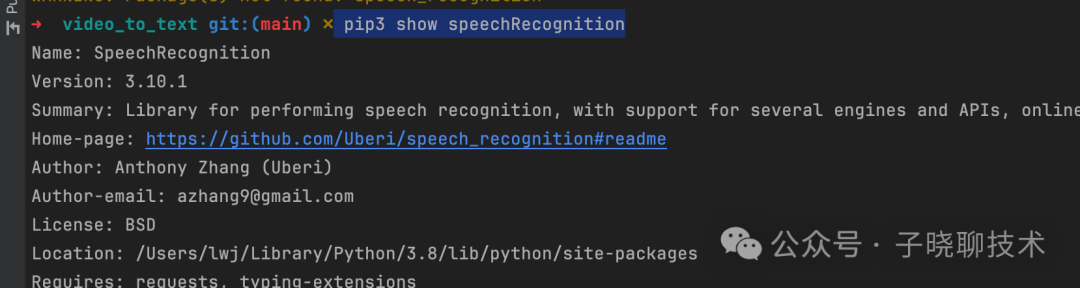
python安装目录下找到Lib\site-packages\speech_recognition: 如果你有很多python安装版本,不知道Python路径,可以通过命令 pip3 show speechRecognition 查找。
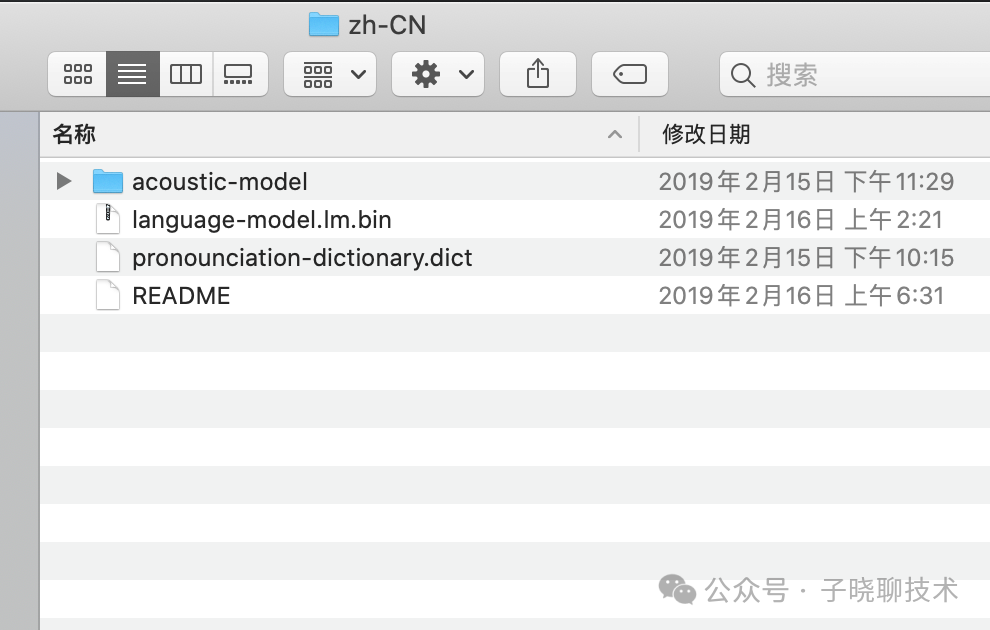
点击进入pocketsphinx-data文件夹,并新建文件夹zh-CN:在这个文件夹中添加进入刚刚解压的文件,需要注意:把解压出来的zh_cn.cd_cont_5000文件夹重命名为acoustic-model、zh_cn.lm.bin命名为language-model.lm.bin、zh_cn.dic中dic改为pronounciation-dictionary.dict格式。
修改了代码 print(r.recognize_sphinx(audio)) 为 print(r.recognize_sphinx(audio, language='zh-cn')) 重新运行 python3 video_to_text.py, 音译的什么玩意。 还是有点牛头不对马嘴。 个人猜想有2个原因,待确定。 1、pocketsphinx离线版中文音译并不理想 2、我这个原视频杂音太多,除了字幕的音频,还有音乐。影响具体的文字识别。后续找个其他视频试一下。 文章先到这里。主要是因为本周末下午天气很好,待会陪小孩玩足球,先不折腾了。 这个只是跑通了流程,并不是太满意实际效果。 未完待续 |
原文地址:https://blog.csdn.net/xiaoliouc/article/details/136989292
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:https://www.msipo.com/article-661421.html 如若内容造成侵权/违法违规/事实不符,请联系MSIPO邮箱:3448751423@qq.com进行投诉反馈,一经查实,立即删除!
Copyright © 2024, msipo.com